Audio Kit.

Audio Kit Overview
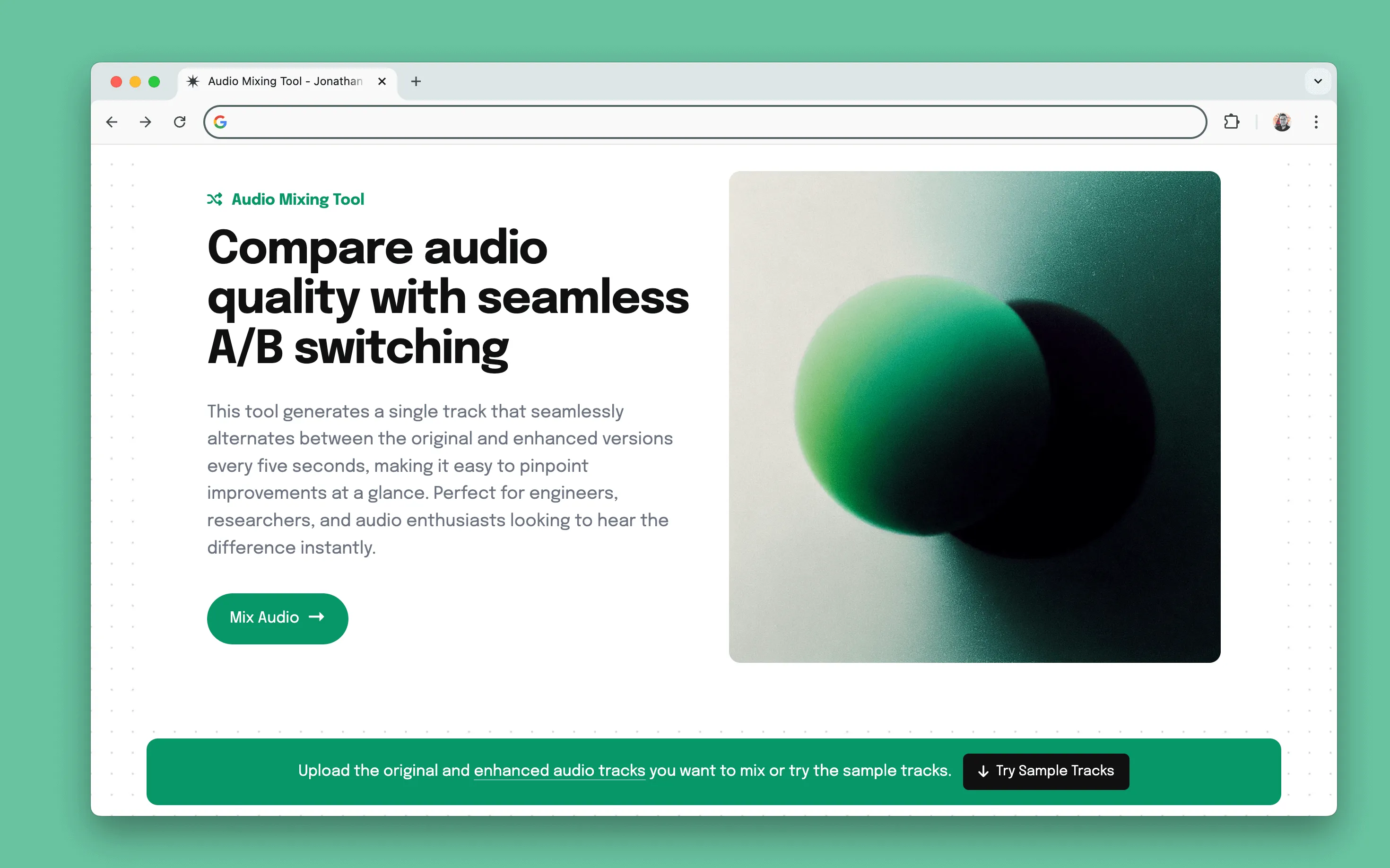
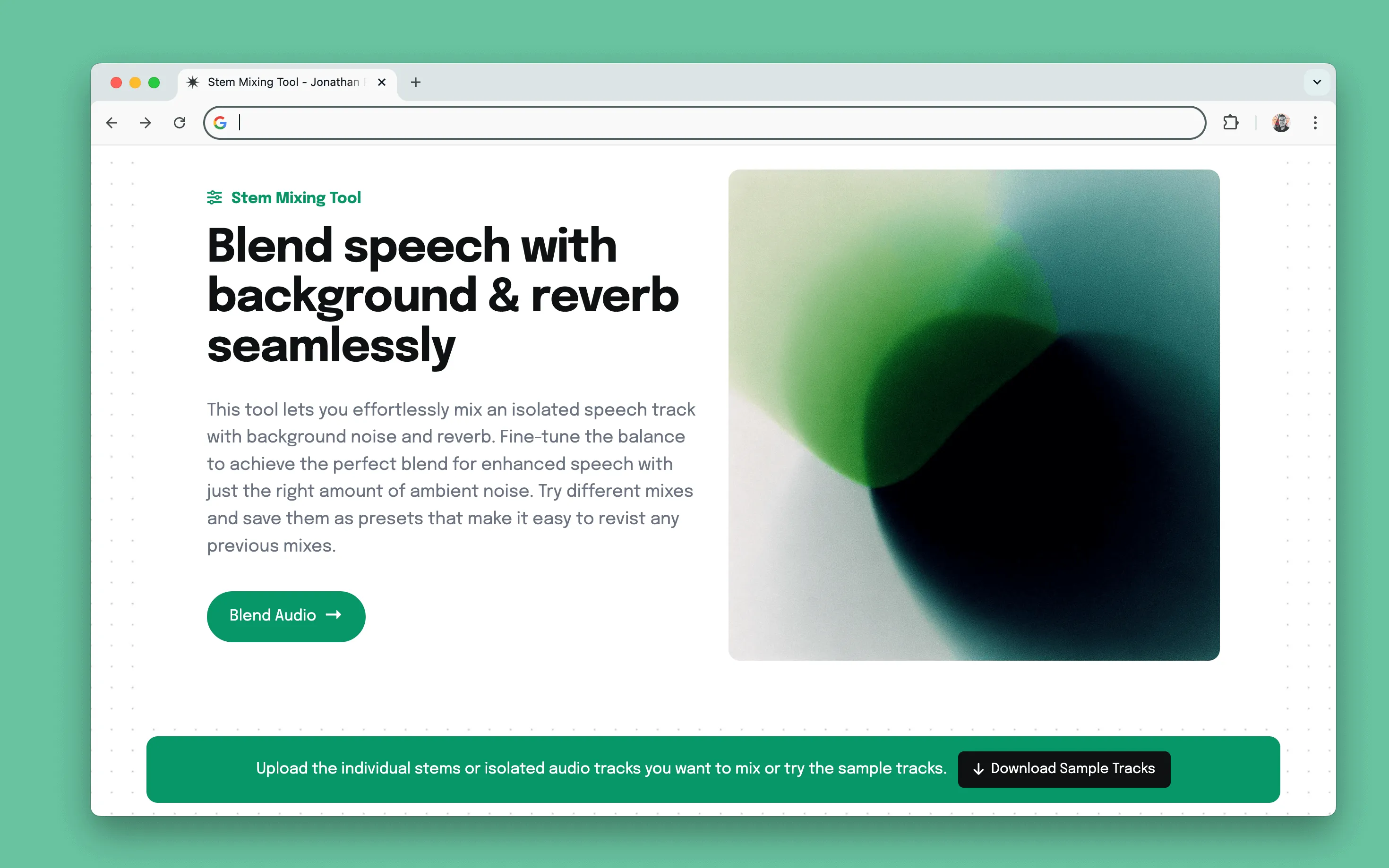
Audio Kit is a set of tools built with Claude and the WebAudio API to streamline model evaluation and testing. I built these while working on Adobe Podcast to automate time-consuming tasks like audio mixing and speech-to-text transcript review.
Track & Stem Mixing Tools
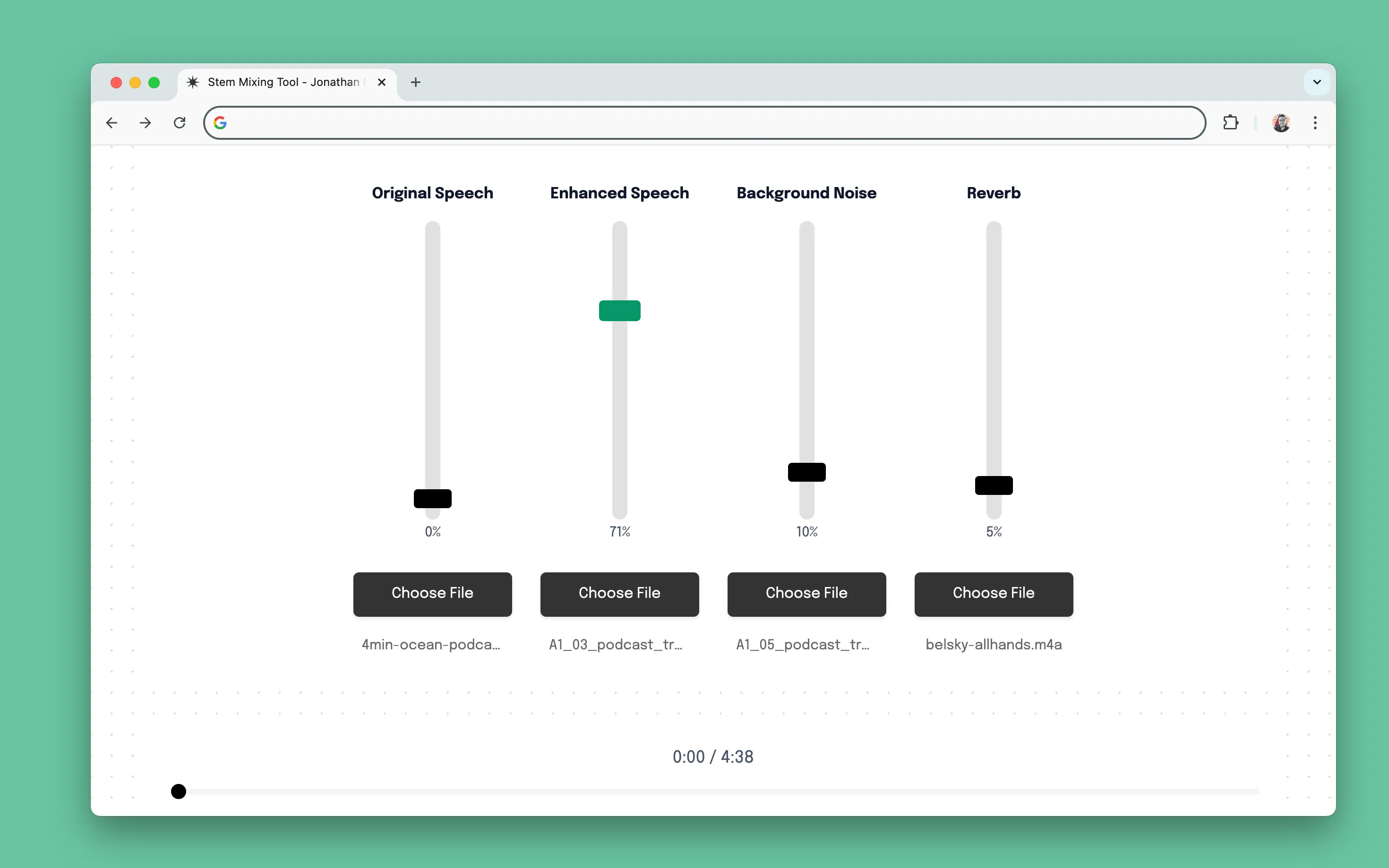
I built tools to simplify audio comparison and remixing. One tool generates an alternating preview of original and enhanced tracks, making it easier to assess improvements without manually switching between files. Another allows real-time mixing of isolated speech, background, and reverb tracks—enabling experimentation without upfront engineering investment.
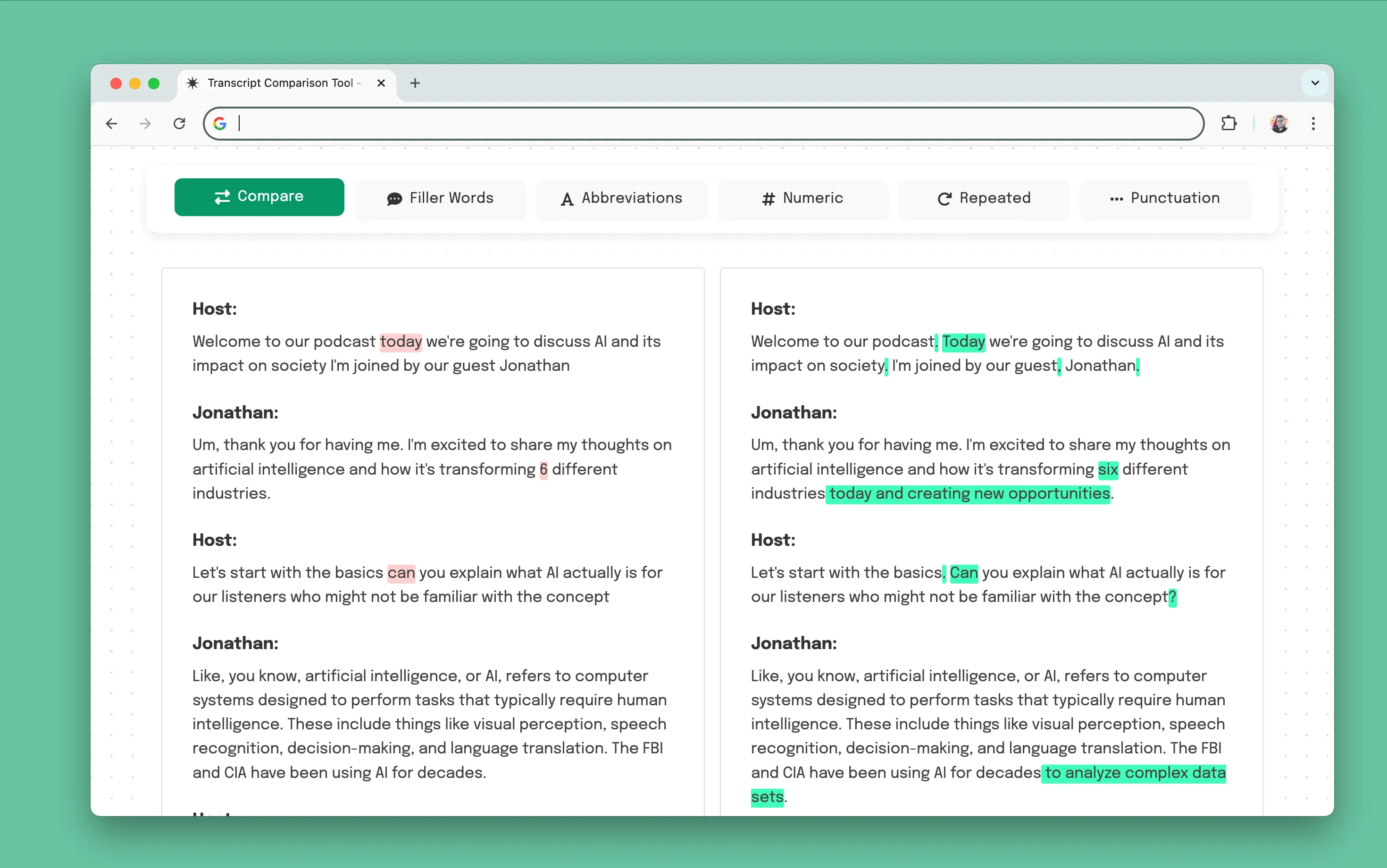
Speech-to-Text Comparison Tools
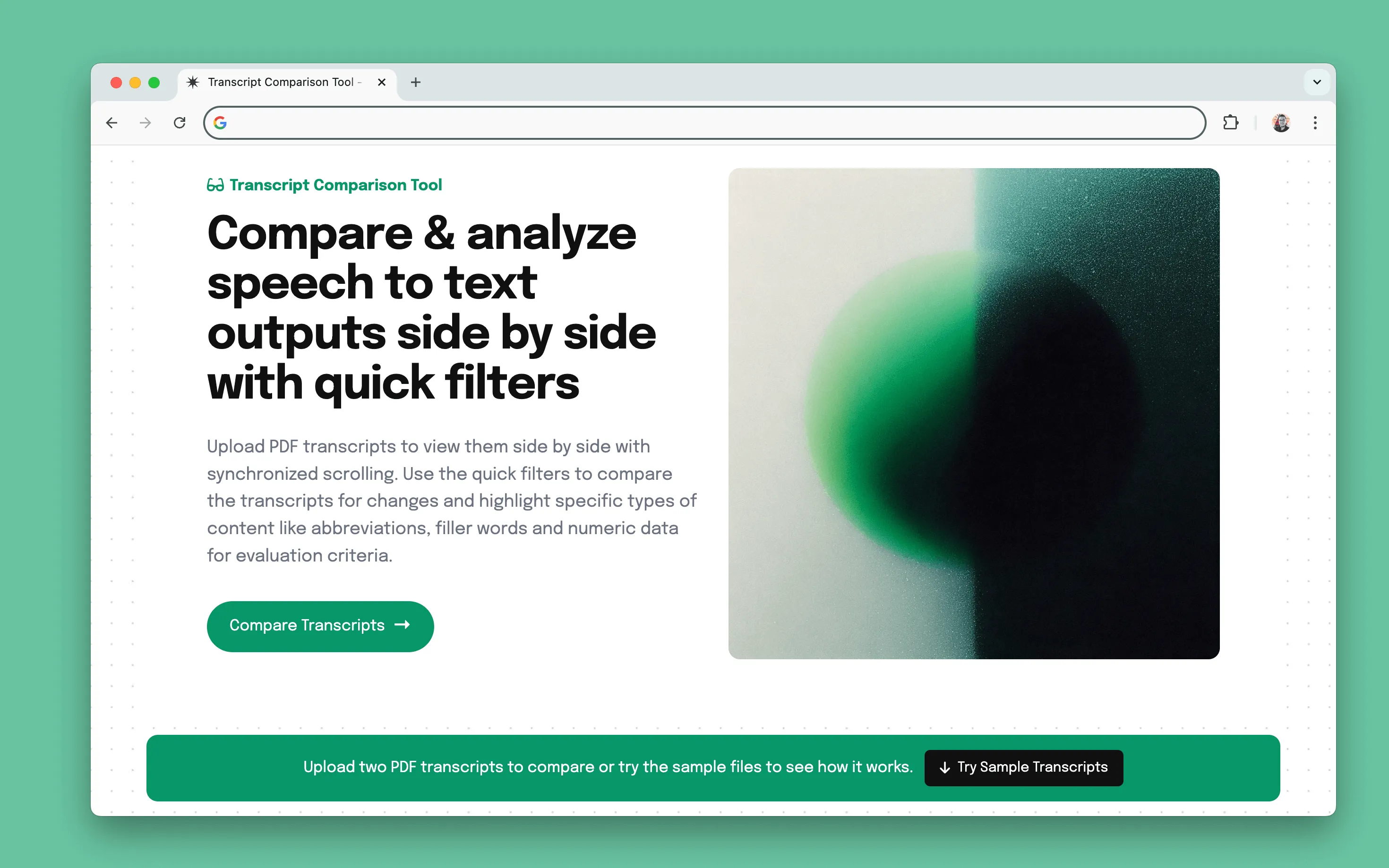
Manually reviewing speech-to-text outputs is tedious and time-intensive. I built a transcript comparison tool using Claude to speed up this step. It allows side-by-side analysis of two transcript versions. It highlights key differences, including repeated words, filler words, numeric data, and other attributes, making it easier to identify discrepancies with problematic content types and refine model accuracy.